VBA×Chrome/Edgeでスクレイピング|XPathとは?|動画で解説

XPathを使うのが一番簡単
この記事はVBA×Seleniumbasic×![]() ChromeでWebスクレイピングを検討されている方向けの記事です。
ChromeでWebスクレイピングを検討されている方向けの記事です。
見ていただくと簡単にWebスクレイピングが出来る様になります。
簡単だと書いている理由はスクレイピング時にXPathを使う為です。
 EnjoyExcel
EnjoyExcelXPathはピンポイントでWeb上の値を指定できるから分かりやすいです。
この記事を見るとわかる事
XPathを使ってスクレイピングができる様になります。
- XPath とは?
- XPath を使うとなぜ簡単なのか?
作業の様子やスクレイピングの様子を記録した動画を用意しています。
動画に合わせてコード&解説も用意しました。
記事のショートカット
XPathは分かっているので動画やコードの説明に進みたい方はこちらから記事をご覧ください。
「XPathとは?」からご覧いただく際はこのまま読み進めてください。
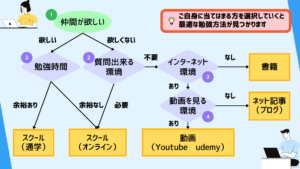
Webスクレイピングは本で勉強しました
Webスクレイピングについて書かれているのは約20ページですがかなり充実しています。
初期設定やWeb上の値を取得する為のメソッドがリスト化されていてすごく見やすいです。
Seleniumbasic(セレニウムベーシック)を紹介してくれている案件は非常に少ないです。
この本を読むとVBAの環境の中でWebスクレイピングが学べます。

XPathとは?
簡単に言うと「データパス」です。データの住所だと考えていただくとイメージできるかもしれません。
WindowsのPCでエクスプローラでファイルパスを指定する事がありますよね。あれと同じだと思ってください。
裏付けを取る為にエビデンスを見てみます。World Wide Web Consortiumからの勧告を引用する事にします。
この団体はWebで使用される技術の標準化を目的として設立された団体です。
WWWCからのリリース「W3C 勧告 2017 年 3 月 21 日」より一部を抜粋しました。
EnjoyExcel日本語版も用意しておきました。
ひとまず太字のところだけおさえてください。
Abstract
XPath 3.1 is an expression language that allows the processing of values conforming to the data model defined in [XQuery and XPath Data Model (XDM) 3.1]. The name of the language derives from its most distinctive feature, the path expression, which provides a means of hierarchic addressing of the nodes in an XML tree.
https://www.w3.org/TR/xpath-31
こちら和訳です。
概要
XPath 3.1 は、 [XQuery and XPath Data Model (XDM) 3.1] で定義されたデータ モデルに準拠した値の処理を可能にする 式言語です。この言語の名前は、その最も特徴的な機能であるパス式に由来します。パス式は、XML ツリー内のノードの階層的なアドレス指定の手段を提供します。
https://www.w3.org/TR/xpath-31
最初に思う事はみなさん同じでしょう。「分かりません」ではないでしょうか。
私はもちろん分かりません。しかし定義というのは正確性が求められます。
よって公的な機関からの情報を引用させていただきました。
分からない中にも手掛かりはあります。それは「パス」というキーワードです。
公的なデータでも「XPathはデータパスに関係するもの」と説明していることが分かります。
このことからXPathはデータへの経路を示す要素だという事が想像できますね。
XPathを使うとなぜ簡単なのか?
理由はシンプルです。「XPathを取得すると欲しい情報までのパスが簡単に取得できるから」です。
情報に対してピンポイントでパス(住所)を取得出来るので細かい事を考える必要がないです。
以降もう少し内容を深堀します。詳細は動画で解説しますのでこのまま記事を読み進めてください。
動画:XPathの取得方法
XPathの取得方法が分かる動画です。
これを見ていただければXPathが欲しい情報までのパスだという事が分かります。
ご注意ください:動画にはHTMLの映像が含まれています
キーワードの配置から状況が読み取れる動画ですのでHTMLの知識が無くても見る事は出来ます。
裏を返せばHTMLを理解出来てない方でもコードを用意する事ができる様になります。

取得したXPathをどう使うのか
あるメソッドの引数としてコード内に貼り付けて使います。
FindElementByXPathメソッドです。ベースとなるコードをご覧ください。
FindElementByXPath(xpath As String) As WebElement
任意で設定の引数は省略しています。よって用意する引数はXPathだけです。
XPathだけあればスクレイピングは出来ます。このメソッドを使ってコードを書いてみます。
基本的にはかっこの中に取得したXPathをそのまま入れるだけです。
そうするとWebElementが返るのでWebElementクラスのtextメソッドで文字を取り出します。
テキストとして取得した文字をCellsプロパティで指定したセルのValueプロパティに代入します。
A1セルにXPathで取得した情報を代入する時のコードをご覧ください。
Cells(1,1) = FindElementByXPath(“取得したXPath”).Text
動画:XPathを使ってリストの情報を取得
XPathを使ってリストの値を取得してみました。動画をご覧ください。

これぐらいの情報なら一瞬ですね。
コード
コードをご覧ください。まずはスクレイピングで使った記事を紹介しておきます。
同じ記事で同じコードを使えばより簡単にスクレイピングを体験いただく事ができます。
記事は随時追加、修正しています。記事の内容が変わるとXPathが変わります。
用意されているコードをそのままコピペして使ってもエラーが出る事があります。ご注意ください。
Sub テーブルの情報を取得()
Dim Driver As New ChromeDriver
Driver.Start "chrome"
Driver.Get "https://www.slt-pgming-21.net/2022-06-11-193321/"
Driver.ExecuteScript "document.getElementById('リスト').scrollIntoView()"
Driver.Wait 2000
Dim 行 As Long
Dim 列 As Long
Dim テーブル列 As Long
For 行 = 1 To 6
For 列 = 1 To 5
If 行 = 1 Then
For テーブル列 = 1 To 5
Cells(行 + 1, テーブル列 + 1) = Driver.FindElementByXPath _
("/html/body/div[1]/div[3]/div/main/article/div/figure[2]/" _
& "div/table/thead/tr/th[" & str(テーブル列) & "]").Text
Next
テーブル列 = 1
Exit For
Else
If テーブル列 = 1 Then
Cells(行 + 1, テーブル列 + 1) = Driver.FindElementByXPath _
("/html/body/div[1]/div[3]/div/main/article/div/figure[2]/" _
& "div/table/tbody/tr[" & str(行) & "-1" & "]/th").Text
End If
For テーブル列 = 2 To 5
Cells(行 + 1, テーブル列 + 1) = Driver.FindElementByXPath _
("/html/body/div[1]/div[3]/div/main/article/div/figure[2]" _
& "/div/table/tbody/tr[" & str(行) & "-1" & "]/" _
& "td[" & str(テーブル列) & "-1" & "]").Text
Next
テーブル列 = 1
Exit For
End If
Next
Next
'ここでコードが終了であれば不要ですので必要に応じて消してください。
Driver.Close
Set Driver = Nothing
End Subこちらもおすすめ各要素毎に取り出すのが面倒だという人はこちらをご覧ください。
テーブルごと一気にエクセルのワークシートに値を取り出す事ができます。
【Selenium×VBA】テーブルの情報を取得|配列を使えば行数と列数も分かる
初期設定は出来ている前提で書いてます
各種設定は以下記事で網羅されています。
初期設定は必須ですので完了していない方は必ず以下記事をご覧ください。
- Seleniumbasicのダウンロード、インストール
- Webブラウザーのドライバーのダウウンロード、設置場所
- Excelの参照設定

コードの解説
構成は5つです。
1、変数にChromeドライバーを定義する
以下記事で解説しております。
2、Googleにアクセスする
以下記事で解説しております。
Driver.ExecuteScript “document.getElementById(‘リスト’).scrollIntoView()” は今回は説明しません。
説明すると少し難しくなるので今回はこのまま書いて使ってください。
動画を撮る際に画面上にスクレイピングの対象となるリストを表示したかったのでコードを用意しました。
本来は不要なコードですので気になる方は消してください。
3、リストの行列を周回する為のループを作る
リストの情報を一気にスクレイピングするのではなく1つずつ(1枠ずつ)取ります。
そのためにはリストを周回する必要があります。6行×5列のループを組みます。
4、1行目の値を取得する
リストの1行目は表題の行です。2行目の2列目から5列目とは異なります。
よってXPathが少し変わりますので1列目だけ別のループを組んでいます。
1列目から順番に値を取得してセルに展開します。
5、2行目から5行目の値を取得する
リストの2行目以降はそれぞれの要素に対する回答(情報)が展開されていますが1列目だけ要素が違います。
1列目もXPathが変わりますので別のループを組みます。
その後は2列目から5列目まで1つのループを組みます。
これで全ての行列から情報を取得する事が出来ます。
繰り返し処理や条件分岐を理解していないと少し難しいかもしれません。
こちらに詳しく説明している記事を用意しておきました。

テーブルの情報を簡単に抜き取る方法
先程紹介した方法ができれば何も問題無いのですがこちらの方法でもテーブルの情報を抜き取る事ができます。
配列が分かる方は紹介する方法を使いましょう。数行のコードだけでテーブル全ての情報を取得できますよ。

省略されたXPathではダメなのか
XPathを取得する際に私はフルパスを取得しています。
パスは2種類あってショート版もあります。どちらを使えば良いのでしょうか?
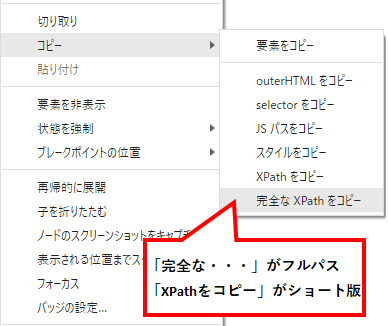
結論としては省略されたXPathでも良いです。コードも短いのでスッキリします。
ただしコードの書き方で気を付けるポイントが増えます。
サンプルとして1つの要素に対してXPathのフルパスとショート版を用意しました。このコードを使って説明します。
こちらの2つのPathは同じ場所から取り出したXPathです。
- //*[@id=”リスト”]/div/table/tbody/tr[1]/td[1]
- /html/body/div[1]/div[3]/div/main/article/div/figure[2]/div/table/tbody/tr[1]/td[1]
ダブルクォーテーションの取り扱いを間違えるとエラーになる
短縮されたXPathでコードを書いてみました。
上のコードと下のコードはほぼ同じコードを書いていますが下はエラーが出ます。違いがわかりますか?
Driver.FindElementByXPath(“//*[@id=””リスト””]/div/table/tbody/tr[” & Str(行) & “-1” & “]/td[” & Str(テーブル列) & “-1” & “]”).Text
コンパイルエラーなのでコード自体が間違っているという事です。
コードが走らないので見た目でエラーを探すしかないです。
Driver.FindElementByXPath(“//*[@id=”リスト”]/div/table/tbody/tr[” & Str(行) & “-1” & “]/td[” & Str(テーブル列) & “-1” & “]”).Text
ダブルクォーテーションが・・・と書いてしまっているので強めのヒントは出しています。
「ダブルクォーテーションダブルクォーテーション」です
答えは@id=・・・後の文字列に対してダブルクォーテーションを2重にする必要があります。
短縮されたXPathで取得されたコードにはひと手間加工が必要になります。
文字列の扱いに慣れてないと難しいのですがコードが短くなるので慣れたら短縮版のXPathを使いましょう。
ダブルクォーテーションの付け方はLike演算子の記事で詳しく書かせていただきました。
必要に応じてご覧ください。

応用編(ハイパーリンク)
FindElementByXPathメソッドを使うとこんなことも出来るようになります。

まとめ
私XPathを使い始めてからはほとんどこの方法を使っています。理由は「簡単だから」です。
欲しい情報に合わせてPathを作っているような感覚なのでどうやって情報を取ろうか考える必要が無いです。
ぜひお試しください。加えてFindElementBy・・・関連のメソッドには便利な機能があります。
例えばXPathを指定してからそのXPathが持つ他の属性を抽出するなんていう事もできます。
関連記事を用意しておきます。
